generator에 대해서 정리를 합니다.

generator의 정의는 generator iterator를 반환하는 함수입니다.
generator iterator의 특징은
- generator iterator는 일반 iterator와 유사하지만 generator에서 yield 구문을 통하여 동작
- generator iterator는 iterator를 사용하는 모든 환경을 대체 가능
generator의 장점은
- iterator에 비해 메모리를 적게 사용
- lazy evaluation 으로 동작
generator에 사용되는 yield에 대한 정리입니다.
Yield
generator가 yield를 만나면 그 상태를 보존하고 있다가, 다시 generator가 호출되면 이어서 수행
yield는 generator에서 값을 반환하거나 값을 입력받는 기능을 수행
다음은 yield 사용 code입니다
3 line의 gen1()은 호출될 때마다 각 yield가 호출하는 값을 return 하게 됩니다.
8 line의 gen2()은 호출될 때마다 yield v 의 값을 return 하게 됩니다.
또한, 22 line의 generator iterator인 g2는 send를 통하여 값을 전달할 수 있는데,
12 line의 code를 보면 send로 gen2() 호출 시, yield에 값이 먼저 전달이 되고 좌측 v에 값을 저장한 뒤, yield는 우측의 v값을 return 하게 됩니다.
next로 gen2() 호출 시, yield는 우측의 v 값을 return 하고 좌측에 None 값을 저장하게 됩니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
#!/usr/bin/python3
def gen1():
yield 1
yield 2
yield 3
def gen2():
v = 1
while True:
v = yield v
print("-----------")
print("v : ", v)
def main():
print("test1")
for g in gen1():
print(g)
print("test2")
g2 = gen2()
print(next(g2))
print(g2.send(3))
print(g2.send(5))
print(next(g2))
if __name__ == "__main__":
main()
|
cs |
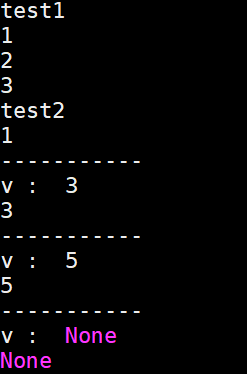
출력 결과입니다.
gen1()의 generator iterator를 for문을 이용하여 출력한 결과 1,2,3 이 출력됩니다.
gen2()의 generator iterator에서 next, send, send, next를 이용한 결과 1,3,5,None이 출력됩니다.
Iterator와 Generator iterator와의 비교
다음은 sample code 입니다.
code를 실행하면 73, 74 line에서 test1() 과 test2()를 실행시킵니다.
test1()은 gen1()으로부터 얻은 list의 iterator를 test 합니다.
test2()은 gen2()로부터 얻은 generator iterator를 test 합니다.
10번의 반복 수행 후 평균 값을 얻기 위해 test_more라는 decorator를 만들고 이용하였습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
|
#!/usr/bin/python3
import time
def gen1(count):
g_list = []
for i in range(count):
g_list.append(i)
return g_list
def gen2(count):
for i in range(count):
yield i
def test_more(f):
def inner(*args, **kwargs):
count = 10
init_t, process_t, total = 0, 0, 0
for i in range(count):
init_t_, process_t_, total = f(*args, **kwargs)
init_t += init_t_
process_t += process_t_
print("%s average - init time : %s, process time : %s, total : %s\n" %
(f.__name__, init_t/count, process_t/count, total/count))
return inner
@test_more
def test1():
t1 = time.clock()
g_ret = gen1(1000000)
t2 = time.clock()
init_t = t2 - t1
t1 = time.clock()
total = 0
for v in g_ret:
total += v
t2 = time.clock()
process_t = t2 - t1
return init_t, process_t, total
@test_more
def test2():
t1 = time.clock()
g_ret = gen2(1000000)
t2 = time.clock()
init_t = t2 - t1
t1 = time.clock()
total = 0
for v in g_ret:
total += v
t2 = time.clock()
process_t = t2 - t1
return init_t, process_t, total
if __name__ == "__main__":
test1()
test2()
|
cs |
시험은 총 1000000개의 integer형 data를 취급하는 것으로 했으며 init, process time 및 해당 data를 모두 더한 값이 동일한지 살펴 보았습니다.
1. 최초 iterator를 얻어 오는 부분은 test1() 이 오래 걸립니다.
※ test1에서 iterator를 가져오기 위해 전체 data를 memory에 올리므로 시간이 좀 더 걸립니다.
※ test2에서 generator iterator는 lazy evaluation을 하므로, 시간이 거의 소요되지 않습니다.
2. data를 for문을 통해 처리하는 부분은 test2가 더 오래 걸립니다.
※ generator iterator의 경우 lazy evaluation 을 하므로 over head가 있는 것 같습니다.
3. 결과적으로 init + process time을 고려하면 generator를 사용한 test2가 좀 더 빠른 모습을 보여줍니다.

'프로그래밍 > PYTHON' 카테고리의 다른 글
| python - Equality, Identity (0) | 2021.02.12 |
|---|---|
| python - Comprehension, Generator expression (0) | 2021.02.11 |
| [환경설정] python - Linux anaconda (0) | 2021.02.10 |
| python - Iterable, Iterator (0) | 2021.02.03 |
| python - Decorator (4) | 2021.01.22 |